Nested models
Most simulations in computational science involve running a single model code, usually either a widely used one like OpenFOAM or GROMACS, or a custom code written by the researcher. To simulate more complex systems, sometimes two codes are connected together using a coupling framework like MUSCLE3.
For really complex systems however, coupled simulations may be needed comprising many parts. For example, tokamak fusion reactors contain a plasma that is kept in place and heated by magnetic fields. The plasma is then heated futher by one or more heating systems, until it ignites and fusion takes place. This generates heat in the form of fast-moving particles, which dissipate their kinetic energy into the plasma.
All this heat is transported from the core to the edge of the plasma, where eventually it is extracted and used to generate electricity. New deuterium fuel needs to be added, tritium needs to be bred and injected, neutrons are produced and collide with the reactor wall producing impurities that enter the plasma, meanwhile turbulence occurs near the edge as the plasma tries to escape its magnetic confinement, and then we haven’t even mentioned the many sensors, actuators and controllers that keep the whole thing stable and running as intended.
An all-up digital twin of a fusion reactor may comprise many codes and software components, making its creation not just an advanced physics modelling exercise, but also an advanced software engineering project. Without a good way of dealing with the inherent complexity of such a simulation, we won’t be able to get it to work.
Nested graphs
In MUSCLE3, coupled simulations are described by graphs. Graphs are visual and intuitive, but their main drawback is that they scale poorly: graphs with many components tend to be difficult to understand, because there are just too many things in them to take in at once.
The most efficient way of dealing with complexity is by introducing a hierarchy. This is common in software, where a script may use some libraries, which in turn are built on top of other libraries, and so on. It’s also how large organisation can function, by having subsidiaries which have branches which have offices, and by having directors who direct one or more layers of managers who manage the workers. In MUSCLE3, this takes the form of nested graphs.
The fusion reactor from our example can be described by a graph with four components: the tokamak with the plasma inside, the sensors, the controllers, and the actuators. Of course this misses a lot of details, but it’s a good high-level overview. We could then zoom in on the tokamak, and create another graph for it containing components for the magnetic equilibrium, transport, sources, and heating. These in turn can each be described by graphs describing e.g. different heating or transport mechanisms, and so on. As a result, we can understand at each level what is going on, without being overwhelmed by the rest of the system.
MUSCLE3 is capable of combining multiple coupling graphs in this hierarchical way, thus enabling complex simulations. We’ll leave the fusion reactor to the experts, and instead use the example from the Uncertainty Quantification section to demonstrate it.
A hierarchical UQ model
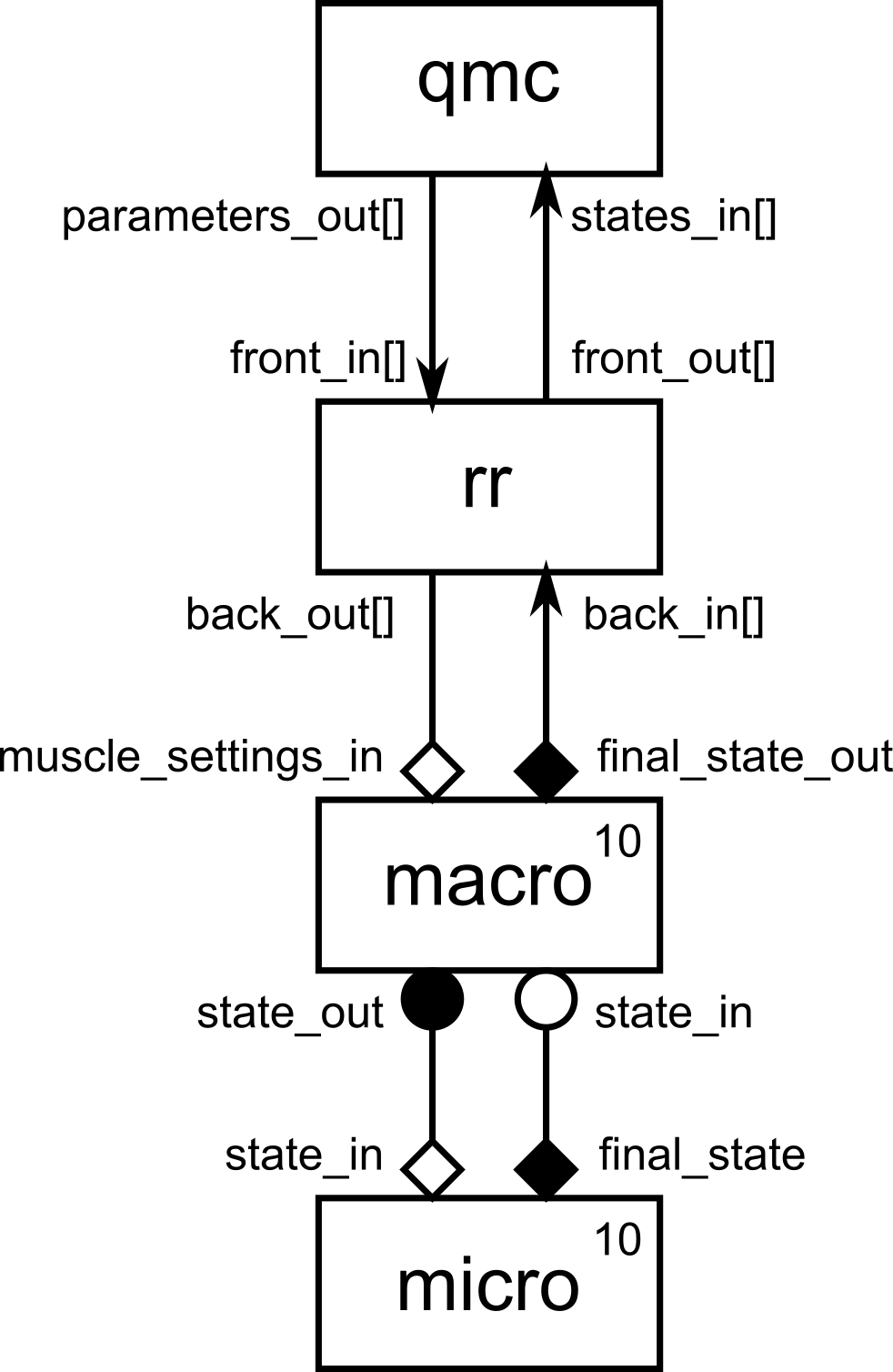
gMMSL diagram of the qMC reaction-diffusion simulation set-up.
The above diagram shows the model from the Uncertainty Quantification section.
This is an ensemble simulation, in which we’re doing a large number of runs of a
reaction-diffusion model, each with slightly different parameter values. The qmc
component draws samples from a distribution to generate a set of parameter values, one
for each ensemble member. To speed up the simulation, we run multiple copies of the
macro and micro components in parallel, with the rr component in between to
send each set of parameters to an available model instance.
In the UQ section, this is implemented as a single model with four components, and as you can tell from the description above, it’s a bit complicated. There are really two different things being combined here: a quasi-Monte Carlo uncertainty quantification (top two components), and a reaction-diffusion simulation (bottom two components). If we model each of them separately and then combine them together, then we can do one thing at a time and make things a bit easier to think about.
Reaction-Diffusion
If you’ve read the other sections, then you’ve already seen the multiscale reaction-diffusion simulation a couple of times. We’re not going to change the model itself, but we will add a new feature: model ports.
docs/source/examples/nested_rdmc.ymmsl, lines 1-30ymmsl_version: v0.2
models:
reaction_diffusion:
ports:
f_init: settings_in # Settings
o_f: final_state_out # 1D array
components:
macro:
ports:
o_i: state_out
s: state_in
o_f: final_state_out
description: |
The macro model implements the diffusion process.
implementation: diffusion_cpp
micro:
ports:
f_init: initial_state
o_f: final_state
description: |
The micro model implements the reaction process.
implementation: reaction_cpp
conduits:
settings_in: macro.muscle_settings_in
macro.final_state_out: final_state_out
macro.state_out: micro.initial_state
micro.final_state: macro.state_in
If we look at the definition above, then we can see the familiar macro and micro
components that we’ve seen before, with the additional final_state_out port from the
UQ example. On lines 5-7 however, there’s something new: the model itself has ports.
We’ve seen port definitions like this before for components and for programs, but not for models. Ports on models allow messages to be received from and sent to the world outside of the model, which makes it possible to connect multiple, nested models together. The syntax for these ports is exactly the same as for components and programs.
In this case, our reaction-diffusion model can receive some settings at the start of its run, and it can send the final state at the end.
To make these ports work, they need to be connected to something. This is done using
conduits, just like when connecting ports between components. In this case, we route the
settings_in port to the macro component’s special muscle_settings_in port
(see Uncertainty Quantification for an explanation of muscle_settings_in),
and we send macro’s final output to the final_state_out port.
quasi-Monte Carlo UQ
Next, we need to describe the uncertainty quantification process. The listing above is
from examples/nested_rdmc.ymmsl, which contains a second model:
docs/source/examples/nested_rdmc.ymmsl, lines 32-62 qmc:
ports:
o_i: settings_out # vector port, Settings
s: final_state_in # vector port, 1D array
components:
mc:
ports:
o_i: parameters_out
s: states_in
description: |
The Monte Carlo driver component samples parameters and collects results for
statistical analysis.
implementation: mc_driver_cpp
rr:
ports:
f_init: front_in
o_i: back_out
s: back_in
o_f: front_out
description: |
The round-robin load balancer distributes runs across the implementations of
the model.
implementation: load_balancer_cpp
conduits:
mc.parameters_out: rr.front_in
rr.front_out: mc.states_in
rr.back_out: settings_out
final_state_in: rr.back_in
Like the reaction-diffusion model, this qmc model has two ports: one for sending
sampled parameters, and one for receiving final states for analysis. We’re using the
O_I and S operators here, because we’re sending and receiving on these ports
multiple times while we’re running. As before, there are conduits to connect the model
ports to the components, in this case to rr.
Combining the models
Finally, we need to apply the uncertainty quantification to the reaction-diffusion
model. The nested_rmdc_model.ymmsl file contains a third model that does just that:
docs/source/examples/nested_rdmc.ymmsl, lines 64-85 rduq:
components:
uq:
ports:
o_i: settings_out # vector port, Settings
s: final_state_in # vecotr port, 1D array
description: |
Implements a quasi-Monte Carlo uncertainty quantification method.
implementation: qmc
uncertain_model:
ports:
f_init: settings_in
o_f: final_state_out
description: |
A model with uncertain parameters to apply UQ to.
multiplicity: 2
implementation: reaction_diffusion
conduits:
uq.settings_out: uncertain_model.settings_in
uncertain_model.final_state_out: uq.final_state_in
This model only has two components, one for the uncertainty quantification process, and one for the model to be quantified. They are connected together using conduits as usual. Note that there are no model ports here, all messages flow within this model, not to or from the outside world.
The rduq model is connected to the others by specifying the other models as
implementations of its components. You can freely mix components implemented by programs
with components implemented by models within a model. To avoid ambiguity, it’s not
allowed to have a model and a program with the same name in a single configuration.
Note that the multiplicity of the uncertain_model component is set here, and will
apply transparently to all components inside of it, including components that have a
multiplicity of their own.
Running nested simulations
Besides the model(s), we’ll also need some settings, programs, and resources to actually be able to run the simulation. We can reuse the program definitions we’ve used with the other models, but settings and resources need to be adjusted slightly to work with the nested models.
The reason for this is that settings may and resources must refer to a specific component that they apply to. In a nested simulation, this is done by specifying a complete component path all the way from the top (outermost) model, rather than only the local name. For example, here are the resource declarations for the nested model:
docs/source/examples/nested_rdmc.ymmsl, lines 105-116resources:
rduq.uq.mc:
threads: 1
rduq.uq.rr:
threads: 1
rduq.uncertain_model.macro:
threads: 1
rduq.uncertain_model.micro:
threads: 1
Resources need to be specified for all components that are implemented by a program. In this case there are four of these. To find the full name, we start at the top model and keep zooming in on components until we get to the program-implemented component. The full name consists of all the components we’ve traversed, separated by periods.
So, for example, to find the reaction model, we start at the top rduq model, pick
the uncertain_model component, look up its implementation which is the
reaction_diffusion model, and inside that find the micro component, which has
the reaction model as its implementation. We’ve passed two components below rduq,
uncertain_model and micro, so the full name is rduq.uncertain_model.micro.
Note that components that are implemented using models, as opposed to programs, don’t
exist at runtime. Any program-implemented components anywhere inside them are
instantiated, and then connected together directly. In this particular model, that means
that there is no instance named uq or uncertain_model, only the four shown
above.
If uq.rr sends a message to uncertain_model.macro via the conduits from
uq.rr.back_out, to uq.settings_out, to uncertain_model.settings_in, to
uncertain_model.macro.muscle_settings_in, then at runtime there’s only a direct
transfer from uq.rr.back_out to uncertain_model.macro.muscle_settings_in just
like in the non-nested version of the model. In fact, other than the component names,
at run time there is no difference at all between the nested and non-nested versions of
this model.
Settings can be specified as before, except that any settings specific to a particular component need to use the full path (without the top model name this time, although this may change in the future for consistency and to enable new features):
docs/source/examples/nested_rdmc.ymmsl, lines 88-102settings:
muscle_local_log_level: INFO
muscle_remote_log_level: WARNING
uncertain_model.micro.t_max: 2.469136e-06
uncertain_model.micro.dt: 2.469136e-08
uncertain_model.macro.t_max: 0.0001234568
uncertain_model.macro.dt: 2.469136e-06
x_max: 1.01
dx: 0.01
k_min: -4.455e4
k_max: -3.645e4
d_min: 0.03645
d_max: 0.04455
n_samples: 10
With all that taken care of, we can now run the model in the usual way:
. python/build/venv/bin/activate
muscle_manager --start-all nested_rdmc.ymmsl rd_programs.ymmsl
Note that the model(s), settings and resources are all in one file here, so that there are only two yMMSL files to pass.
Discussion
Splitting up monolithic models (or computer programs in general!) into a separate pieces is an excellent way to reduce complexity. In this example, the most complex model in the original version has four components and six conduits. In the nested version, the maximum complexity is two components and four conduits. This makes it easier to understand each piece.
This improvement does not come for free however, because the overall number of items has increased. Across the three models, we now have six components and ten conduits. If you cut your software into smaller and smaller pieces, then the overall amount of code will increase, and the additional code will become less and less meaningful.
So when designing models, the trick is to find a good middle ground. Can you understand your model? Can a person new to it easily grasp it? Then you should not split it up. If you frequently find yourself having to look up how some part worked again, and you have trouble explaining it to newcomers, then perhaps it’s time to see if you can find a good submodel to split off.
Importing implementations
In the above example, we have put all three models in a single file, with the programs in a separate one. For smaller models built by a single person this is fine, but there comes a point where it’s easier to split the model across different files. Similarly to how this works in most programming languages, we can import models and programs from a different yMMSL file and use them as implementations.
As an example, here is the reaction-diffusion submodel of our nested UQ model in a separate file:
docs/source/examples/ymmsl/reaction_diffusion.ymmslymmsl_version: v0.2
imports:
- from rd_programs import implementation diffusion_cpp
- from rd_programs import implementation reaction_cpp
models:
reaction_diffusion:
ports:
f_init: settings_in # Settings
o_f: final_state_out # 1D array
components:
macro:
ports:
o_i: state_out
s: state_in
o_f: final_state_out
description: |
The macro model implements the diffusion process.
implementation: diffusion_cpp
micro:
ports:
f_init: initial_state
o_f: final_state
description: |
The micro model implements the reaction process.
implementation: reaction_cpp
conduits:
settings_in: macro.muscle_settings_in
macro.final_state_out: final_state_out
macro.state_out: micro.initial_state
micro.final_state: macro.state_in
Without imports, we’re allowed to pass to the manager a yMMSL file with the model and one or more files with the programs, and MUSCLE3 will combine all that information to run the simulation.
With imports, the rules are a bit stricter, because we’re now making a large piece of software and it will become too difficult to keep track of what to pass when. Instead, in imported yMMSL files, all implementations that are used need to be available in that file, either because they’re specified there, or because they are imported.
Our reaction-diffusion model above specifies two implementations, which are imported at the top:
docs/source/examples/ymmsl/reaction_diffusion.ymmsl, lines 3-5imports:
- from rd_programs import implementation diffusion_cpp
- from rd_programs import implementation reaction_cpp
The imports section contains a list of import statements. Vertical lists in YAML start
with a - for each item, and after that is the actual import statement. Import
statements have a form similar to Python:
yMMSL import statement
from <somewhere> import <kind> <name>
The <somewhere> part specifies where to import from. This works the same as in Python:
you write names separated by periods, and those refer to subdirectories and finally a
file. So, a.b.c refers to a file a/b/c.ymmsl that we’ll be importing something
from. In the reaction-diffusion model, we’re importing from rd_programs.ymmsl, which
contains the program definitions we want to use.
The <kind> part specifies what it is that we want to import. As of MUSCLE3 0.9.0, only
one kind is supported, implementation. This can be either a model or a program, and
we can’t really tell from the import statement which of those the thing we’re importing
is, but that’s okay because we don’t need to know: both programs and models can be used
as implementations and that’s what matters.
Finally, the <name> part is the name of the program or model that we want to import, in
this case diffusion_cpp and reaction_cpp.
In Python, which has a very similar syntax, there are a few other ways in which you can write an import statement, like importing multiple names from a single file in a single line, and importing something under a different name. MUSCLE3 does not currently support these, so you’ll have to write your import statements exactly as shown above.
Running a simulation with imports
Besides the above reaction_diffusion submodel, the nested UQ model consists of two
more models, the qmc one and the top-level rduq model. You’ll find qmc in
examples/ymmsl/uncertainty.ymmsl, and a version of the top-level model that uses
imports in examples/nested_rdmc_imports.ymmsl. Have a look at those files and see if
the imports make sense.
With the import statements in place, we can now run the model by starting
muscle_manager with only nested_rdmc_imports.ymmsl on the command line. However,
we do need to point out to MUSCLE3 where it should look for files to import from,
because it can’t know how we have set up our folder structure. This is done by setting
an environment variable called YMMSL_PATH.
YMMSL_PATH contains a list of directories separated by colons, just like PATH,
PYTHONPATH, and LD_LIBRARY_PATH if you’re familiar with those. When an import is
needed from a.b.c, then MUSCLE3 will look at each path in YMMSL_PATH in turn
from left to right, add /a/b/c.ymmsl, and try to import from that file.
The files we’re importing from nested_rdmc_imports.ymmsl are all in
examples/ymmsl/, so all we need in our YMMSL_PATH is that directory. If you’re
using bash and are in the examples folder, then this will set YMMSL_PATH
correctly:
export YMMSL_PATH="${PWD}/ymmsl"
${PWD} is the present working directory, and then we add the subdirectory to that.
Next, we can run the simulation using
muscle_manager --start-all nested_rdmc_imports.ymmsl
The result will be exactly the same as for the integrated model, but now we have separate files that can be maintained separately, possibly by separate people.